写了个小网页,实现的功能是:
- 1.在前端网页选择项中选择指定内容;
- 2.传送给后端服务器,查询数据库找出相应的内容;
- 3.并把这些内容存放Excel表格后,把下载链接提供回前端页面上显示。
然后下载数据文件。
写了个小网页,实现的功能是:
然后下载数据文件。
用的 Keep主题,主题的配置文件中关于这个Valine 评论的配置就以下内容:
1 | # Valine |
本文记录一些自己使用过的SQL语句,以及在Python中的应用。
用 Python处理Excel中的数据,把以下图片中的图一转到下面图二的形式:
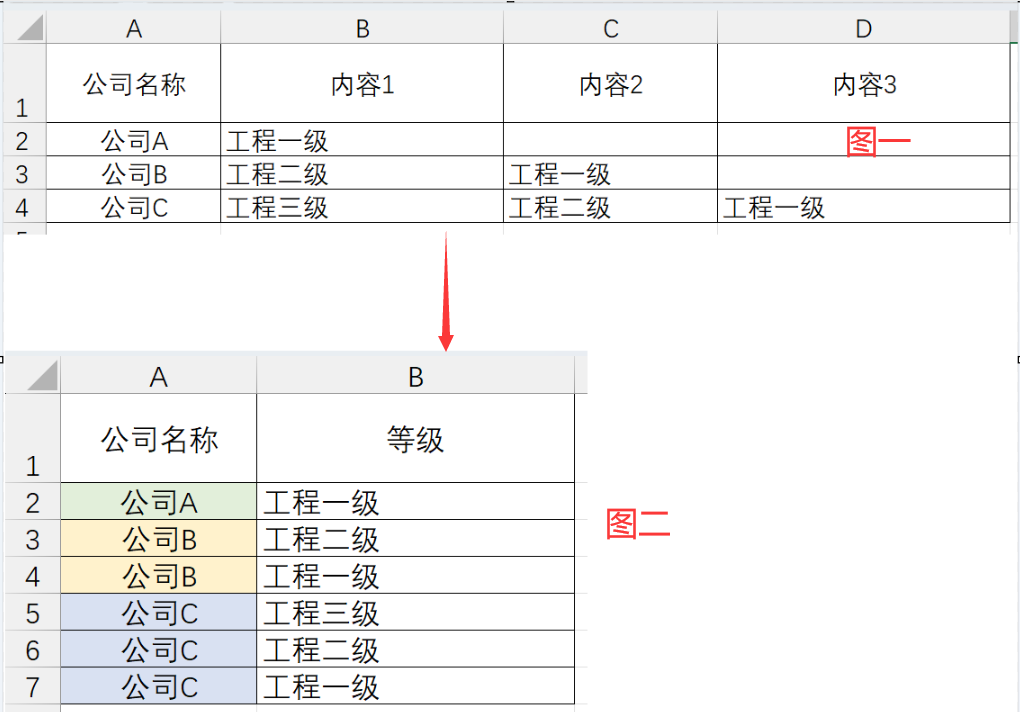
就是一个列转到行。
解决思路:
笔记本装的是win11家庭版,没有装Hyper-V。因为想装Docker Desktop,偶尔测试用,所以就把 Hyper-V装起来试一下。
这个应该是Python低版本都会碰到的错误,我用的Python3.8.6就报错了,比这个低的版本可能都会有这个错误。
报错信息如下:
1 | # 运行 pip install turtle |
1Panel 是一个开源的 Linux 服务器运维管理面板。
安装很方便,运行一条命令就安装好了。
原来一直没用面板,主要就是都用的Docker,所以也不用看什么,基本上命令就够用了。
不过随着Docker中的容器越来越多,先是装了个 LazyDocker 来看。突然看到这个开源的管理面板工具,就试了下。感觉还不错。
在Python中,我们经常需要对小数进行四舍五入操作。四舍五入是一种常见的数值处理方式,可以将小数精确到指定的位数。Python提供了多种方法来实现小数的四舍五入操作。
原因是这样的:
用手机拍了四五百张照片后,用苹果手机连接电脑,想导入到电脑里。
然后发现了这个问题:连接电脑后,在电脑上看到了像U盘盘符的Apple盘符,打开后发现照片不全;如果在手机相册中打开某张没有的照片,再在电脑中打开就能看到这张照片,不知道什么bug,感觉是没加载全的。
为了快速找到到底缺了哪些照片,因为图片文件名都是按序号递增的,就想用到Python直接检查一下好了。毕竟少了好几十张,手动找起来真的麻烦死了。
pytesseract是Python的一个OCR文本识别库。
以下几点概括了它的主要信息:
Github项目地址:https://github.com/tesseract-ocr/tesseract