当Python要操作Excel表格时,用Pandas库就超级方便了。
Pandas的主要数据结构有Series(一维数据)与DataFrame(二维数据)。
用来操作Excel表时,最常用的就是DataFrame了。
安装pandas库
1
2
3
4
5
6
7
8
|
pip install pandas
pip install openpyxl
pip install xlwt
|
最后保存成.xls格式的时候,会有如下提示:
1
| As the xlwt package is no longer maintained, the xlwt engine will be removed in a fuine will be removed in a future version of pandas.
|
这个东西在pandas中会被淘汰,不用管,等以后不能用了再说。
毕竟还是有些破系统的导入,只支持xls格式的。不过,自己肯定是能用xlsx就用xlsx。
使用举例
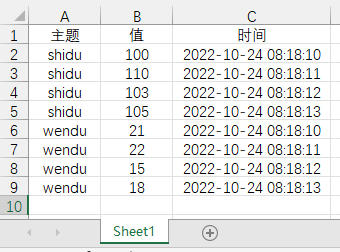
以以下表格(data.xlsx)举例:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import pandas as pd
import numpy as np
def read_ex_01(ex_file):
df = pd.read_excel(ex_file)
print(df)
def read_ex_02(ex_file):
usecols = ['主题', '值']
sheet_name = 'Sheet1'
df = pd.read_excel(ex_file, sheet_name=sheet_name, usecols=usecols)
print(df)
def read_ex_03(ex_file):
df = pd.read_excel(ex_file)
data_list = np.array(df).tolist()
print(data_list)
def write_to_ex01(ex_file):
name_list = ['张三', '李四', '王五']
name_pinyin_list = ['zhangsan', 'lisi', 'wangwu']
data_dict = {'姓名':name_list, '账号':name_pinyin_list}
data = pd.DataFrame(data_dict)
data.to_excel(ex_file)
def write_to_ex02(ex_file, new_col, data_list):
dr = pd.read_excel(ex_file)
col_name = dr.columns.tolist()
col_name.append(new_col)
dr.reindex(columns=col_name)
dr[new_col] = data_list
dr.to_excel(ex_file, index=False)
ex_file = r'.\data.xlsx'
read_ex_01(ex_file)
read_ex_02(ex_file)
read_ex_03(ex_file)
write_to_ex01(r'.\ex\data1.xlsx')
write_to_ex02(ex_file, '账号', ['zhangsan', 'lisi', 'wangwu'])
|
还有使用Pandas的文章: